This post explores how bias can creep into word embeddings like word2vec, and I thought it might make it more fun (for me, at least) if I analyze a model trained on what you, my readers (all three of you), might have written.
Often when we talk about bias in word embeddings, we are talking about such things as bias against race or sex. But I’m going to talk about bias a little bit more generally to explore attitudes we have that are manifest in the words we use about any number of topics.
Word Embeddings
If you’re one of my three regular readers, you might remember that I’ve already introduced word embeddings I trained on FDA records. In February 2023, I wrote a post on using NLP to assess FDA’s compliance with notice and comment in guidance development.[1] About halfway through that post, in connection with Word Mover’s Distance as a means of comparing the similarity of two guidance documents, I explained the concept of a word embedding and the use of multiple dimensions to capture the meaning of a given word. The explanation includes a chart that shows simplistically the difference between the words “happy” and “sad” in terms of positivity versus negativity. While the chart is simplistic, the model I created included 300 dimensions for measuring the meaning of words.
Specifically, I trained the word embeddings I used on roughly 600 medical device guidance documents from the FDA’s website, as well as about 40,000 510(k) summaries also pulled from FDA’s website. Thus, the authors of the training data include both FDA officials working presumably as committees, and regulatory affairs professionals at companies who draft the summaries. That’s why I’m suggesting that my language model reflects the thoughts of my readers, because I’m assuming many of my readers are regulatory affairs professionals either in industry or at FDA.
Are you interested in what collective biases there might be in your writings? If not, I guess you’re done reading my post for the month.
Bias Evaluation Using Sentiment Analysis
There are many different ways to evaluate potential bias in word embeddings, but I didn’t want to do a survey article where I talked briefly about all of them. Instead, I thought I’d pick just one approach for illustration. The one I picked is perhaps the simplest, which is an evaluation of the word embeddings using a model for positive versus negative sentiment. In other words, I’m looking to see whether particular word embeddings have a largely positive or negative connotation.
If words that should be regarded similarly have significantly different sentiments or connotations, that would be evidence of bias. In other words, if the word “black” as an adjective for people has a largely negative connotation while the word “white” as an adjective for people has a largely positive connotation, that would be some evidence that the embeddings, trained on what people have written, have absorbed from that training data a bias against black people.
However, I’m not going to use race as my example in the analysis below. For one thing, race is rarely discussed in FDA documents, apart from a handful of documents specifically on race. I will leave you to draw your own conclusions from that. Instead, I’m going to look for bias in other topics.
Methodology
I wanted to keep it simple, so I will not use any of the cool, sophisticated, but complicated techniques that recently have been developed. Instead, for this first foray into the topic, I’m going to use a methodology that’s been around for a while because it’s relatively simple to understand. In fact, I’m shamelessly mimicking an approach used by Robyn Speer in her July 2017 post entitled “How to make a racist AI without really trying”. I’ve updated the methodology only slightly to account for changes in software libraries since she published her article.
The basic approach is to train an algorithm – specifically a classifier – to recognize the differences between positive and negative words. In my particular case, I chose to use a random forest classifier from sklearn because it has shown to be effective in this sort of analysis.
This is an exercise in supervised learning, meaning that the algorithm needs to be trained by being told which words are positive and which words are negative in a training set. For that, I used a list of words that have been labeled as either positive or negative that most researchers in this space use, data created by Hu and Liu which are available from Bing Liu’s web site[2].
Here’s the theoretical part. To recap, I have thousands of words that researchers have labeled as positive and thousands of words that researchers have labeled as negative. I also have thousands of these word embeddings through my prior machine learning work defined by 300 dimensions. The idea is that one or more of those 300 dimensions might correspond to positive versus negative connotations of the word. Thus, in theory, if I take the positive and negative words labeled as such from Hu and Liu, and if I represent those words using my 300-dimension word embeddings, I can train a machine learning classifier to spot positive versus negative words using the embeddings that I created from training on the FDA regulatory documents. In other words, the algorithm can learn which of the 300 dimensions in the word2vec model I created correspond to positive versus negative sentiment.
So that’s what I did.
Validation
I like to document the uncertainty of any algorithm I use. I withheld about 10% of the data so I could test the algorithm on labeled data to see how well it did. I went into this assuming that I could perhaps get 90 to 95% accuracy from this exercise because that’s what Robyn in her original article achieved. But I couldn’t. The best I could do was approaching 80% accuracy.
I spent a fair amount of time, for example, using grid search to experiment with different hyperparameters, and I also experimented with adding additional data for training purposes from other data sets. Oddly enough, adding more training data caused the performance to go down. Ultimately, I concluded that this was about the best I could do.
If you ask me why my performance was lower than Robyn achieved, Robyn was analyzing some common word embeddings developed from training data such as Google News. In comparison, my training data were scientific and regulatory documents. While there are many differences between those data sources, at a high level I would say that regulatory professionals use fewer adjectives and adverbs in their writing. But adjectives and adverbs are the food of sentiment analysis. Without adjectives and adverbs, the algorithm has far less to go on in categorizing words as positive or negative. A sentence “the results were a score of 16” just doesn’t give the algorithm much to go on as to whether those words are positive or negative.
Or maybe I’m just bad at it. But in any event, not quite 80% accuracy was the best I could do. Keep that in mind.
Validation Through Visual Exploration
Another way to validate the appropriateness of the algorithm that is little bit less scientific and relies much more on the anecdotal and the visual. I wanted to see how the results look, so I decided to assess an entire FDA guidance document on this negative versus positive sentiment to see what it looked like. Obviously, an FDA document could be skewed positive or negative. I decided to go with one of the longer documents just because of regression to the mean. For a longer document, there should be positive and negative sentiment in the document. I therefore picked --not randomly --FDA’s September 2022 guidance on “Clinical Decision Support Software.”[3] I picked it because it was one of the longer guidance documents that I analyzed back in February, so I already had much of the code written. That’s probably not a great reason.
But I wanted to see what the distribution of words were on this positive versus negative scale, and I wanted to weight them by the frequency of the word used in the guidance. This is what that frequency looks like in graph form.
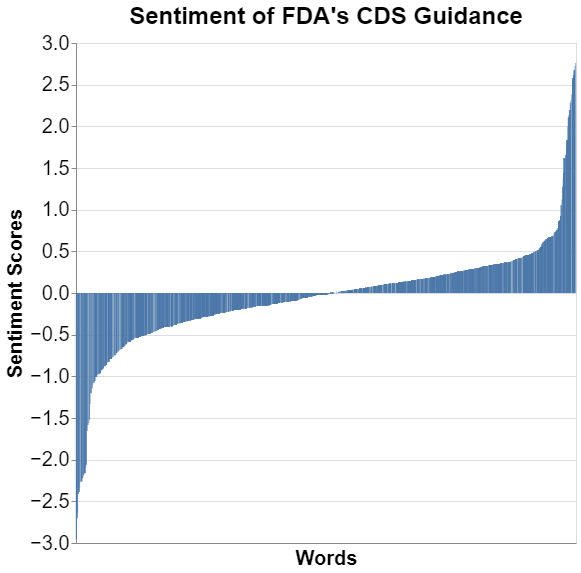
I’ve sorted the words from most negative to most positive. I didn’t list the words on the x-axis because, well, there are thousands and you wouldn’t be able to read them.
Just eyeballing it, I think it looks pretty good. The words in the middle are obviously more neutral, and then you have the two extremes. The extremes look somewhat symmetrical. But I never trust my eye when I’m trying to gauge, for example, how much is positive versus how much is negative, so I thought I would run a simple calculation and take the average of all words used. That average turned out to be 0.0086400. You really couldn’t expect much closer to zero. Thus, on the whole, in this particular guidance document, the negative sentiment words are pretty much in balance with the positive sentiment of words. I’m not sure what that means but with my OCD tendencies I always like symmetry.
Truly Anecdotal Validation
Okay, so big picture it looks sort of reasonable although I have no objective evaluation of what the average of that particular guidance document should be. But why don’t we look at a few individual words to see if their positive / negative scores seem intuitively correct. Remember that correct should be whatever we anticipate a group of FDA regulatory scientists thinking.
Let’s compare two random words / phrases.
| Words | Sentiment score |
| “medical professional” | 0.2645 |
| “attorney” | -0.2699 |
Okay, well that seems about right.
I should point out that I really don’t have any evidence to suggest that the absolute level of a sentiment score is all that accurate. As a result, what I focus on is comparing words to see if the comparisons ring true. So here are a variety of comparisons I tried, selecting words that are somewhat common in FDA regulatory writing.
| Words | Sentiment score |
| “safe and effective” | 1.8191 |
| “adverse events” | -1.1846 |
| Words | Sentiment score |
| “notification” | 0.4109 |
| “alarm” | -2.2675 |
I always suggest that clients use the word “notification” instead of “alarm,” and now I have the data to back that up.
| Words | Sentiment score |
| “hospital” | -0.1968 |
| “at home” | -0.3431 |
It’s kind of interesting that hospital is a bit negative, although certainly from a popular perspective people don’t want to be at the hospital. But it’s also interesting that “at home” is more negative through the eyes of FDA regulatory professionals.
One of the things that I noticed is that because of the way this algorithm is designed, evaluating sentences which include lots of words necessarily moves the score toward zero because the algorithm is just taking an average of the words, so with more words you regress to the mean. But even so, and even with many words the same, the algorithm does reasonably well with certain sentences.
| Words | Sentiment score |
| “the device clinical trial was successful” | 0.1353 |
| “the device clinical trial was a failure” | -0.5736 |
I also want to just remind you again that the algorithm is only about 80% accurate, so there are some results that caused me to scratch my head like this one.
| Words | Sentiment score |
| “the device saved many lives” | -0.0079 |
| “the device had few side effects” | -0.1665 |
Remember too that the algorithm is just analyzing words, not sentences, so it doesn’t catch the profoundly different meaning that words such as “not” or “few” convey in giving sentiment analysis to a sentence.
With those limitations, it seems as though the algorithm analyzing the sentiment of words created in the word embeddings is at least interesting if not somewhat accurate.
Results
What does all this tell us about whether there is bias in these word embeddings I created by training on FDA regulatory documents? Let’s continue with a few comparisons in areas where I wondered if there might be bias.
Over the nearly 40 years I’ve been practicing FDA law, I get the sense that FDA regulatory professionals have sometimes strong opinions about the countries from which data are gathered. Let’s see if there are any differences.
| Words | Sentiment score |
| “Mexico” | 0.0783 |
| “China” | 0.0435 |
| “United Kingdom” | 0.1112 |
| “Russia” | -0.5466 |
| “France” | -0.1220 |
| “Japan” | 0.3084 |
| “Foreign data” | -0.3008 |
| “data” | 0.1719 |
| “foreign clinical trial” | -0.3959 |
| “US clinical trial” | -0.1458 |
I need to start by observing that many of those differences are not statistically significant. We are dealing with some small numbers here frankly all clustered around neutral. But there are some stark differences, such as the difference between say Japan and Russia.
It’s important to remember that the training data set is just the premarket review summaries as well as generally FDA guidance documents. There’s really not much of that training set from enforcement or quality contexts, so this really wouldn’t reflect FDA enforcement views.
I included the last four to show a more global level sentiment around foreign data versus data more generally. I honestly can’t explain why the U.S. clinical trial sentiment would be negative.
I thought I would assess the sentiment of some regulatory words.
| Words | Sentiment score |
| “recall” | 0.0337 |
| “warning letter” | -1.0746 |
I like the fact that recall is more neutral because it is simply the responsible action of a manufacturer to address the occasional but unavoidable quality issue, where warning letter has a decidedly negative connotation.
I then wanted to assess product words to see if there are connotations associated with different specific or even general categories of products.
| Words | Sentiment score |
| “software” | 0.4422 |
| “hardware” | 0.4782 |
| “in vitro diagnostics” | -0.0399 |
| “acupuncture” | 0.2168 |
| “pedical screw” | -0.2985 |
| “ventilator” | 0.2377 |
| “infusion pump” | -0.1383 |
| “minimally invasive” | -1.1198 |
| “aid in diagnosis” | -0.2770 |
| “pediatric” | -0.1878 |
I will let you draw your own conclusions from those, but again, keep in mind, only 80% accurate and the magnitude of the actual scale has not been validated in any way. I really do not understand the “minimally invasive” result.
I could go on, but I’ll close with this. I mentioned above that I didn’t see much point in including race in this discussion because so few documents discuss it. I think more discussed is sex because sex has long been recognized as a factor that needs to be considered. Consider these sentiment scores for the sexes.
| Words | Sentiment score |
| “man” | -0.7500 |
| “woman” | -0.2115 |
I will let you draw your own conclusions from that.
Conclusions
The whole point of this exercise is to illustrate that any word embeddings, because they are trained on human input, will have biases. That’s true because no human being on earth is free from bias, so any machine learning model trained on that human input will have those biases.
We must be aware of those biases in all natural language processing, and more than that we must find them and then account for them. It often is impossible to remove them, but there are other coping mechanisms we’ve developed such as explicitly considering the existence of the bias.
In the future, I’ll dive deeper into this topic because I find it personally interesting, but it’s also one that I think many companies need to consider on a more sophisticated basis.
* * * *
The Unpacking Averages® blog series digs into FDA’s data on the regulation of medical products, going deeper than the published averages. The opinions expressed in this publication are those of the author(s). Subscribe to this blog for email notifications.
[1] https://www.healthlawadvisor.com/2023/02/01/unpacking-averages-using-nlp-to-assess-fdas-compliance-with-notice-and-comment-in-guidance-development/
[2] https://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html#lexicon
[3] https://www.fda.gov/regulatory-information/search-fda-guidance-documents/clinical-decision-support-software