It is certainly easy, when writing code to accomplish some data science task, to start taking the data on face value. In my mind, the data can simply become what they claim to be. But it’s good to step back and remember the real world in which these data are collected, and how skeptical we need to be regarding their meaning. I thought this month might be an opportunity to show how two different FDA databases produce quite different results when they should be the same.
Background
For context, I should explain that I didn’t set out to find differences in the FDA data sets. Rather, since one of my areas of interest is FDA regulation of combination products, and in particular digital combination products, I wanted to get a sense of in which product codes I might find digital combination products.
To do that, I needed to create two different lists of 510(k) submissions, one for all submissions that include the word “software” in the 510(k) summary, and then one for all medical devices in the 510(k) process designated as a combination product. I could then look for the intersection of those two lists.
Now I admit that simply searching for the word software is a bit crude. For example, it’s possible that such a search would find a sentence that says something like “no software is used in this device.” But we don’t have in the FDA system any formal designation for something called a digital health product. The word “software” seems like a word that is pretty likely to show up if the product is digital and further it seems as though the trend is to add software to new technology, not subtract it. It would be unusual for a 510(k) summary for a new device to basically say that it is less sophisticated than the predicate device in that it has deleted the need for software. If anything, the word “software” is probably too inclusive because it would include any submissions that simply mention software even if the software isn’t a very central part of the device’s functionality. But it seems acceptable to me as a starting point and I can always then manually go through the output to see whether the search results make sense.
Consequently, the left side was easy, but I thought about how to get the right side –those 510(k)s where the product is appropriately designated as a combination product, or more precisely the medical device constituent part of a combination product. For whatever reason, while FDA’s 510(k) database includes a field for the designation as a combination product, when that data set is made available through openFDA, that field is not included. I don’t know why, and frankly I hope the FDA changes that. In a somewhat cumbersome step, instead of going to the openFDA APIs, I simply used the 510(k) database itself. I used combination product as a search criterion, and then manually extracted that search result and worked with that.
I then had the idea of testing those search results by going to the Unique Device Identifier (UDI) database I used for my blog post last month because that database also includes a field for whether a product is designated as a combination product.
Below are the two outputs, assembled those two different ways.
Findings
Here’s the output when I used UDI as the source of my assessment of whether or not a 510(k) was for a device constituent part of a combination product.
Chart A--Using UDI data
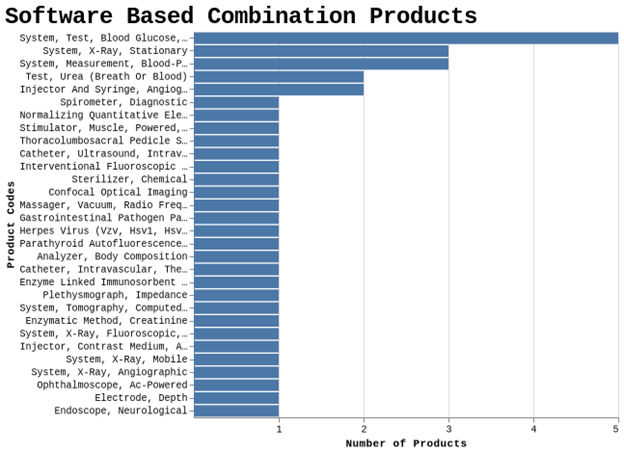
Honestly, that looks surprising to me based simply on my understanding of what some of those product categories include when compared to my downloaded search results from the FDA’s 510(k) database. Here are those results.
Chart B--Using Data From the 510(k) Database
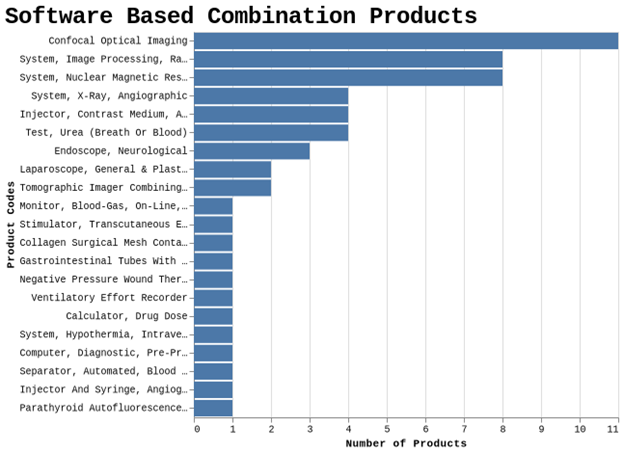
They look pretty different.
Methodology
As already indicated, the list of software 510(k)s is a direct, simple search of the 510(k) summaries for the word “software.” I say it was simple, but obviously there was a technical challenge because those summaries are not released in the openFDA project, so I had to download every single 510(k) summary as a PDF file, and read the PDF files into a database before I could search it. But I used that list – the identical list – in producing both charts. That side didn’t change.
As already observed, the source of the so-called truth about whether a given submission was part of a combination product did change between the two charts. One of the differences between the two databases--510(k) database and the UDI database-- is that the 510(k) database is longitudinal – it exists over time – where the UDI database is supposed to be a comprehensive snapshot list of those devices presently on the market. For the 510(k) database, I went back 12 years because I thought that would be adequate to capture digital combination products of interest. Using software in connection with drugs is a relatively new product category.
Interpretation
So why are the charts so different? Not only do the lists seem to include many different categories, but the quantities are also quite different.
Starting with the data from the UDI, the fact that pedicle screws are included in the list caught my eye. At first, I had to verify that there were even pedicle screw products that had software, and turns out there are. The software directs how to use them. But why would they be listed as combination products?
For background, here’s FDA’s regulatory classification for Thoracolumbosacral pedicle screw system (21 CFR Sec. 888.3070:
(1) Rigid pedicle screw systems are comprised of multiple components, made from a variety of materials that allow the surgeon to build an implant system to fit the patient's anatomical and physiological requirements. Such a spinal implant assembly consists of a combination of screws, longitudinal members (e.g., plates, rods including dual diameter rods, plate/rod combinations), transverse or cross connectors, and interconnection mechanisms (e.g., rod-to-rod connectors, offset connectors). (Emphasis added.)
I’m guessing some young regulatory person filled out the UDI form for their product to indicate that these are combination products because they are a combination of multiple devices, not because they meet the definition of a combination product at FDA.
So, the weakness of the UDI database is simply that it is whatever manufacturers fill it out to be. And obviously it is possible to make mistakes. But does that explain all of the differences?
On their face, the data from the 510(k) files seem like they would be more accurate. Similar to the UDI database, the 510(k) database is based on input initially from companies. During the 510(k) submission process, at least presently, the eSTAR system asks the company to designate whether the device is a combination product or not. While in earlier days when that system was not used, it’s my understanding that for many years applicants have been required to designate whether their product is a combination product or not. In FDA’s Principles of Premarket Pathways for Combination Products Guidance proposed in 2019 and made final in 2022, FDA expressly requires applicants to identify whether the product is a combination product based on a statute ((21 U.S.C. 353(g)(8)(C)(v)) that was enacted in December 2016. Therefore, it seems like it’s been relatively clear since about 2016 that sponsors had a legal obligation to identify whether their device was a constituent part of a combination product. That said, as with the UDI database, it is possible for the manufacturer to be mistaken in identifying whether its product is a combination product.
The difference is that, during the review process, the reviewer confirms whether the product is a combination product or not. For example, the cover sheet memorandum and the acceptance checklist for traditional 510(k)s require the FDA reviewer to express an opinion on whether the product is a combination product or not. Thus, the data in the 510(k) record is probably not overinclusive, but it might be underinclusive if an applicant for whatever reason fails to declare that their product is part of a combination product.
But the graphs still looked tremendously different.
Conclusion
My point in writing this post is pretty simple. We should never just assume that the data are what they’re supposed to be. All of these data are the product of human thought and data entry, and it is possible that there are mistakes – indeed many mistakes – and also simply different purposes for recording the data.
I started off to write a post to help those interested in digital combination products. Perhaps you can glean some knowledge there as well, perhaps by looking at the union of the two different graphs but looking critically at each product category. If you are looking for a predicate device for digital combination product, you might find leads either place that can be confirmed by reading the actual 510(k) summary for the device.
* * * *
The Unpacking Averages® blog series digs into FDA’s data on the regulation of medical products, going deeper than the published averages. The opinions expressed in this publication are those of the author(s). Subscribe to this blog for email notifications.