Continuing my three-part series on FOIA requests using a database of over 120,000 requests filed with FDA over 10 years (2013-22), this month’s post focuses on sorting the requests by topic and then using those topics to dive deeper into FDA response times. In the post last month, I looked at response times in general. This post uses topic modeling, a natural language processing algorithm I’ve used in previous blog posts, including here[1] and here[2], to discern the major topics of these requests.
Findings
As I’ll discuss in more detail below, it turns out an optimal number of topics to use for sorting is 20. Remember that the algorithm isn’t reading these as a human would, but that’s also not a bad thing. The algorithm is looking for requests that are composed using similar words.
It’s important again to appreciate that this is a blend of art and science. The actual data set is comprised of about 120,000 different requests submitted by tens of thousands of people, each with different motivations along a sort of continuum. The topics are quite human and messy. They don’t fall into cookie-cutter topics. Some requests are very similar, some are pretty similar while others might be only slightly similar. There is no reason to believe that the categories would be obvious and completely distinct from one another. Below in the first visualization, I depict the relationship among topics along two artificial dimensions, just so that you can see that some topics are distinct while others overlap.
In the first chart, I present the topics in an interactive graphic that you can access by clicking on the image below. Once you click on the image, you can move your cursor over the topics represented by circles on the left-hand side (which as I mentioned above shows the relationship among the topics in two dimensions), and the chart will highlight the terms on the right-hand side that are relevant to defining that topic.
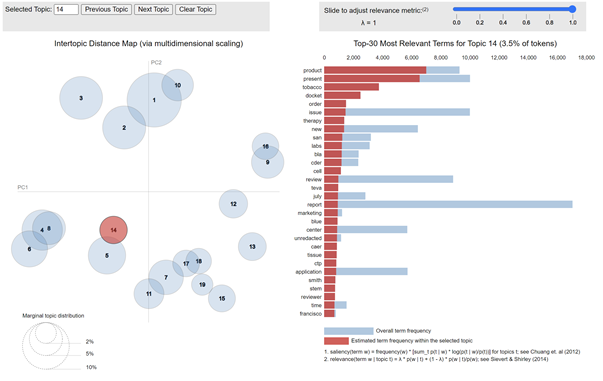
If you prefer the more static presentation of the topics, here are the 20 topics with each of the keywords listed in order of importance and the magnitude of that importance identified. Just to confuse you, while the interactive chart lists the topics from 1 to 20 in the way regular people think, the following lists topics from 0 to 19, the way computer scientists think. So you need to adjust each topic by one.
One further note. The topics are not identical. I used slightly different algorithms to compose the two different charts. They’re very similar, but they’re not identical. The math is slightly different. But in that sense, given the difference in math and yet the similarity in outcome, the two charts validate the approach.
Word Count and Importance of Topic Keywords

Some of those topics are easier to understand and interpret than others. The ones that seem to fall into somewhat defined categories include the following:
- 2. Complaint Investigation/Adverse Events
- 3. Drug Inspections
- 4. 483/EIR Drug
- 6. NDA/Adverse Event Report
- 7. Warning Letters
- 9. Specific Correspondence
- 11. Follow-On FOIA
- 12. 510(K)
- 13. Indian 483
- 17. Meeting Minutes
- 18. Medical Device Inspection
I would encourage you, however, to look at the actual graphic presentation above and especially look at the ones where I haven’t labeled them, because they might be meaningful to you from your own perspective. For those that I didn’t think lend themselves to a pithy title, I simply continue to refer to them by number.
With those topics identified, I then wanted to see which ones were more frequent than others. The interactive chart above gives an indication of prevalence by the size of the circle on the left-hand side. But with the static presentation, I thought I would graph it in a bar chart. This data, as with all data I will present, covers the entire database over the 10-year period.
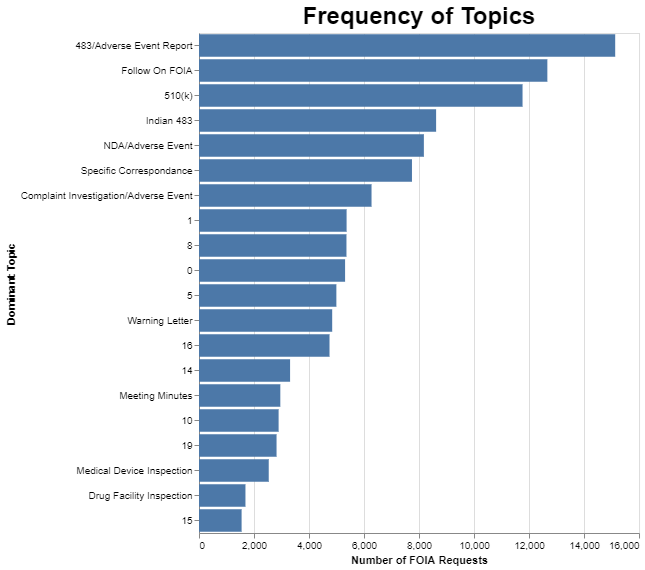
The so-called follow-on FOIA request is a request that piggybacks on a prior FOIA request, and asks for the same information that was provided to the previous requester. It’s a strategy for speeding up the process because it alerts FDA that they’ve already done what’s being asked.
Given that data on frequency, I wanted to see FDA response times broken down by these same topics.
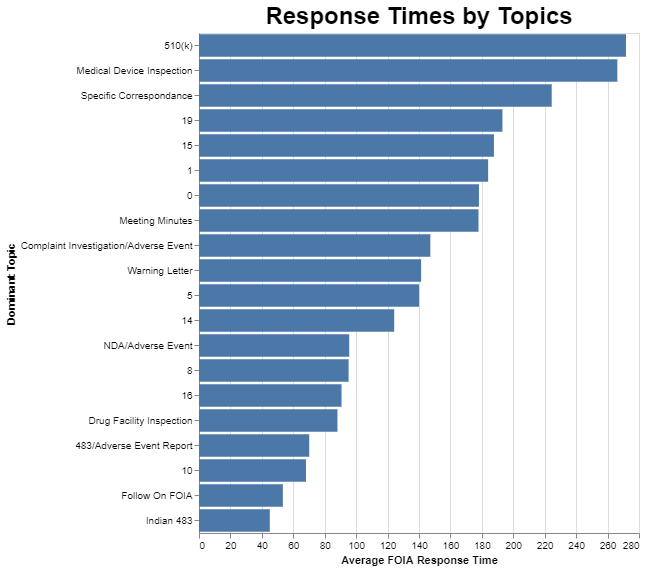
We will discuss the implications of this data more under the interpretation section below, but I like to assess from a quality standpoint whether the data are believable and reasonable. Just a quick review reveals significant differences in response time between, for example, requesting a copy of a submitted 510(k) that must be reviewed for confidential information and redacted, and the response time for a follow-on FOIA where the previous response simply needs to be identified and shared with the new requester.
But we can also dig deeper. Rather than just rely on the average response time for a given category, to unpack the averages we can look at the response times for a specific topic. And they vary considerably.
To do this, I chose both the longest response time and the shortest response time, and as I did last month in the graphs I presented, focused on the lower left-hand portion of the graph, in this case chopping off the tail that goes to the right at an arbitrary 500 days.
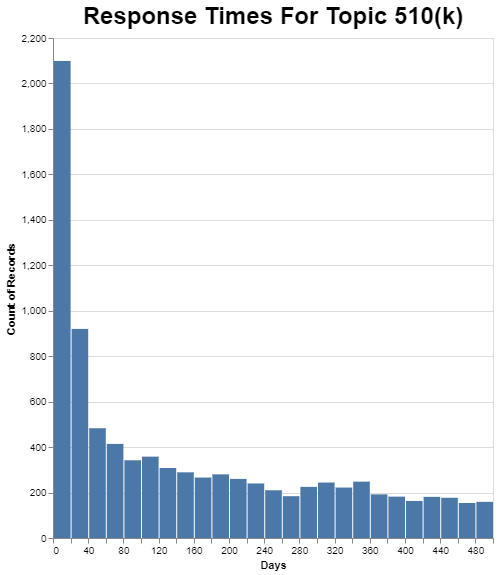
Remember that 510(k) is one of the most common FOIA requests. Despite that, there are few, comparatively speaking, 510(k) FOIA requests completed in the first 20 days. If you go back to the chart on frequency, there are nearly 12,000 510(k) FOIA requests in this ten-year data set. Only about 2100 get resolved in the first 20 days, or about 18%. As I mentioned, I cut the chart off at 500 days, but there’s a very long, thick tail that goes to about 2500 days.
Contrast that with response times for the Indian 483’s.
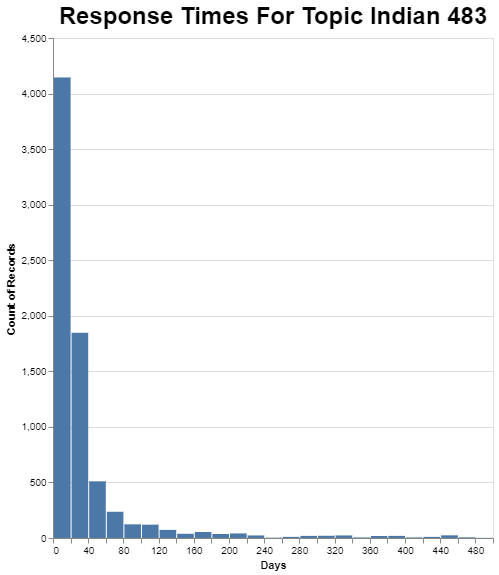
Perhaps not surprisingly since the response time on average is pretty good, a very large number of these are completed in the first 20 days, or about 4100 of 8100 or nearly 50%, and the tail falls off quickly to the right.
I will talk more about interpreting all of this data in the section on interpretation. But first, I want to share more about the methodology because that helps lay the groundwork for the interpretation.
Methodology
As I’ve said before, this whole exercise is a blend of art and science because we are trying to interpret text written by literally tens of thousands of different people. Here is some of the most significant processing I did to the text.
- The particular Python libraries I used tended to simply remove numbers as if they’re unimportant, but that did not serve me well with such things as 483’s. To address that, I converted those numbers to words, in that particular case “foureightthree”. That’s a pretty crude solution but it works.
- It’s important to remember that software really isn’t smart. The FOIA requests included all sorts of K numbers in specific format like k190267. To the software, each one of those was different, but you and I know that they are all just references to 510(k) submissions. As a result, I converted every K number to the word “Knumber” so the software could identify common themes.
- In a similar vein, when requests reference another request to piggyback on it, they simply reference it by the standardized format for a FOIA request reference number. The software didn’t recognize those as related, so I converted them all to “FOIAnumber” and the light went off in the computer’s brain.
- One of the factors I had going for me is the fact that the text in the database is not the text of the actual FOIA request, but a summary of the FOIA request by an FDA staff person. That’s fortunate, because it means that people who use the same standard way of writing wrote all of them. There were a bunch of abbreviations, but once you figure out what they are, I simply converted them to the underlying words they represented.
- I got rid of a specialized set of words that were frequent but really meant nothing in this particular context. I removed words like “file”, “document”, “request” and so forth.
- I also used the standard techniques such as reducing each word to its root so that the software would recognize that “event” and “events” were really the same.
- I added so-called bigrams (two words that go together), because often two words together have a new and specialized meaning that each word individually does not convey. The word “warning” has a pretty general meaning, as does the word “letter,” but you put them together and get “warning letter,” and all of a sudden that has a specialized meaning in this FDA context. Here’s another place my coding was a bit crude. The particular libraries that I was using wanted to strip out all of the punctuation, so I couldn’t create bigrams that read, for example, warning_letter. I had to smoosh them together into one word—‘warningletter”—to fool the software.
- For the actual topic modeling, I used several libraries including nltk, spacy and genism. To select the number of topics, I used the coherence score c_v, employing LdaMulticore and CoherenceModel from genism. Turns out that 20 topics is ideal. It produced a coherent score of just under 0.6 which is pretty good. Coherence is simply how well the words of a topic hold together, creating logical consistency. If I tried only 19, the algorithm would combine FOIA number with K number into one category, apparently because they were so short and simple and involved just the presence of one type of number. Coherence dropped off rapidly after 20 topics.
Interpretation
As mentioned above, the first thing I did is ask myself whether the results made sense. The fact that the very most requested information is Form 483’s with ancillary information makes sense to me because, for one thing, that cuts across all product areas at FDA – food, drugs, medical devices etc. Further, I know from my own work, but also what I read from the media, that lots of people are interested in trying to understand the issues that FDA is raising in Form 483’s. The fact that FDA now has an enforcement dashboard[3] that allows for the release of this information may mean that it isn’t likely to be such a popular FOIA request over the next 10 years. But over the last 10, its popularity makes sense.
In a similar vein, a follow-on or piggyback FOIA request would also, I expect, be quite popular because it is used across all product areas and it is a standard technique for reducing the wait time to get results.
Getting down to specific program areas, 510(k)s in the medical device arena are immensely popular to obtain because you can learn so much about a competitor but also about the regulatory pathway for your product. Thus, the fact that it’s toward the top also makes sense.
The one that surprised me is in the fourth position, the Indian 483’s. I had no idea that was so popular, so I went into the data to look at a sampling of them. Turns out there are over 2200 FOIA requests related to Form 483’s for Indian facilities from a variety of media, private equity, information merchants, pharmaceutical companies and a whole lot of others. Who knew?
But my chart above actually suggests there are over 8000 such requests, which doesn’t turn out to be true. This raises an important point. The word India is fourth on the list of relevant words to topic 13, so perhaps it isn’t fair to characterize the entire topic as related India. It really seems much more about inspectional 483’s. And in that sense, the topic seems to overlap with topic number four which also is focused on 483’s, but in equal measure focused on Establishment Inspection Reports, or EIRs. The topic modeling algorithm is finding a subtle distinction between those two. This takes me back to my very first point when presenting this data, these are not neat, clean, separate and distinct topics.
With that reminder, let’s focus on the average response times broken down by category. It seems logical that the 510(k) requests would be at the top because those are frequently lengthy documents that must be reviewed through a very manual process at FDA, and with the help of the applicant, to remove any confidential commercial information before they are released.
In fact, on FDA’s FOIA website, they warn that 510(k) requests take a long time. Specifically, FDA says[4] “Please note that requests for 510K, PMA, and De novo records are complex requests and take approximately 18-24 months to process.” FDA’s statement, however, seems a bit pessimistic because the average time for these requests according to the data is about nine months. It kind of feels like FDA wants to discourage these requests. Either that, or FDA has gotten substantially slower over the last 10 years in responding to these requests.
One category that caught my eye was the request for specific correspondence. I think the reason such a request can take so long is that often the request is not for a specific letter, but rather for all correspondence between XYZ company and the FDA. Thus, it would take the agency a while just to collect all of that correspondence, and then redact it.
It makes sense to me that the follow-on FOIA requests would be comparatively quick to get responses because that’s the whole purpose of them. People are requesting information that’s already been supplied so it doesn’t need to be collected and redacted.
As I mentioned above, it’s also possible to go deeper and look beyond the averages for these 20 topics to see how long it takes to get responses. I picked two perhaps extreme examples. The 510(k) example is one where a lot of review and redaction needs to occur, but I’m still surprised that the amount of time it takes is so highly variable. If the process is roughly the same for each one, even though the length of 510(k) documents can vary widely, that difference in the documents wouldn’t seem to justify the significant difference in the amount of time it takes to respond. In the chart, each 20 day increment has a substantial number of responses. Why would that be? Recall also that I simply cut the days at 500, but the raw chart continues on for many hundred days after that with a pretty thick tail. This one’s a puzzle to me.
At the other end, what I’m calling the Indian 483’s have a very short average response time, so it makes sense that there is less variability in the individual responses. Most of these get responded to right away.
Conclusion
As I explained at the start, topic modeling is an art because it’s an interpretation of a large amount of data with, in this case, tens of thousands of different authors. Each author is fundamentally looking for something slightly or significantly different along multiple different dimensions. Thus, there are degrees of similarity between requests along multiple continuums: it’s not a matter of distinct categories. It’s a bit more liberal arts and a bit less engineering.
Nonetheless, as a liberal arts major, I find value in knowing even generally, and even subject to all of these limitations, what types of requests take longer to get a response, and what types might comparatively sail through the FOIA process.
Next month, I will finish up this look at FOIA data by taking this topic modeling paradigm, and looking at the data in terms of outcomes. Some people get what they want through the process, while others don’t. It’s important to understand your chances of success based on the general flavor of the request you are making.
* * * *
The Unpacking Averages® blog series digs into FDA’s data on the regulation of medical products, going deeper than the published averages. The opinions expressed in this publication are those of the author(s). Subscribe to this blog for email notifications.
ENDNOTES
[1] https://www.healthlawadvisor.com/2021/11/01/unpacking-averages-analyzing-descriptions-from-cardiovascular-device-adverse-events/
[2] https://www.healthlawadvisor.com/2022/10/03/unpacking-averages-using-natural-language-processing-to-extract-quality-information-from-mdrs/
[3] https://datadashboard.fda.gov/ora/cd/inspections.htm
[4] https://www.fda.gov/regulatory-information/freedom-information/how-make-foia-request