I recommend against relying on any data I provide in today’s post. I hope the data are at least somewhat accurate. But they are not nearly as accurate as they should be, or as they could be, if FDA just released a key bit of information they have been promising to share for years.
One of the ways data scientists can provide insights is by grafting together data from different sources that paint a picture not seen elsewhere. What I want to do is join the clinical trial data at www.clinicaltrials.gov with the data maintained by FDA of approved drugs, called drugs@FDA. But I can’t, at least not with much accuracy.
The key piece of missing information is the clinical trial identifier number that clinicaltrials.gov assigns to every clinical trial posted there. I have the numbers from that website managed by the National Library of Medicine within NIH, but when FDA shares its database of approved drugs, FDA deletes that identifier number, generally referred to as the NCT number. Without knowing the specific NCT number of the studies that were used as a basis for approving a particular drug for a particular indication on a particular date, I can’t connect the dots back to the clinical trial information posted on clinicaltrials.gov.
That’s frustrating, because if FDA supplied that identifier number I would know exactly which trials were used to support which approvals, and by joining the two databases, I could glean all sorts of insights about what kind of evidence FDA actually requires to obtain a specific kind of FDA drug approval.
FDA’s Position on Releasing the NCT Numbers
FDA knows they should release the numbers, and promised to do so four years ago. They just haven’t. The agency recognizes that releasing that information is a key component of being transparent, of letting the public understand the basis for drug approvals. For the agency to have credibility in what it does, the public needs to be able to see what kind of trials are required to gain approval. Right now, we can’t, not with any confidence. It involves a lot of guesswork which I’ll share below.
Then FDA Commissioner Scott Gottlieb announced that the agency would do this in 2018. Specifically, in a blog post, he explained:
A significant number of publicly and privately supported clinical trials register on the National Institutes of Health’s database, ClinicalTrials.gov, which provides easy access to information on studies in a wide range of diseases and conditions. Many of the global trials listed on ClinicalTrials.gov relate to research involving new drugs, and may eventually form the basis of an application seeking FDA approval. Yet right now, tracking a specific clinical trial listed on ClinicalTrials.gov and correlating that trial to its relevance in informing FDA related activities – from advisory committee meetings to FDA approval decisions and to the inclusion of the results of a clinical trial into a drug product’s label – can be challenging.
So, another way we plan to help foster greater transparency around clinical research is adding to FDA materials for future FDA drug approvals the ClinicalTrials.gov identifier number (called the NCT #). This number will make it easier to associate the clinical trial listings on ClinicalTrials.gov to FDA communications about specific drugs, including product labeling and even our advisory committee meeting materials. Members of the patient, academic and scientific communities can easily use this number to identify and track clinical research from a drug’s development throughout the regulatory process. Including this number on FDA materials could greatly benefit all those interested in following the progress of specific clinical research.
If only FDA had actually done it. For weeks I have been reaching out to dozens of people at FDA all the way up to the Chief Information Officer asking them what their plans are to follow through with Dr. Gottlieb’s 2018 announcement, and have gotten no response.
By the way, CDRH already provides these NCT numbers in connection with cleared 510(k)'s in the 510(k) database. It's only CDER which appears to be lagging.
Methodology
I will outline, just for context, my own attempts to estimate which trials go with which approvals. You will see how messy and awkward and unreliable it is.
As a data scientist, I’m interested in large trends and correlations, so my goal is to associate the hundreds of FDA new drug approvals with the even greater number of clinical trials used to support them. Most approvals require at least two trials, so we are talking about large numbers. As a result, it’s not feasible to do this on a manual basis, but instead needs to be done by analyzing data sets comprised of English language data representations, computer fields such as the names of drugs and the particular diseases or conditions for which they are being evaluated.
Thus, the first challenge is analyzing the two databases – the drugs@FDA data set and the clinicaltrials.gov data set – to isolate exactly which drugs are involved in each. That sounds like it would be simple, but it’s not. The names of the drugs are entered in slightly different ways that make matching them in an automated way uncertain.
After trying to match the two data sets on the name of the drugs, then it becomes a matter of figuring out which diseases or indications are at issue in the two different data sets. Again, analyzing English language expressions is always riddled with errors. The data set creators don’t label the diseases or conditions in exactly the same way.
Then finally, even if you believe that you’ve isolated the correct name of the drug and the correct name of the condition, it’s a matter of connecting the clinical trials that were used for a particular application based on the timing of when the trial was conducted versus when the approval was granted. It’s also then a matter of making sure that you are only considering phase 3 clinical trials if you’re looking for what might’ve been submitted in support of an application. There are plenty of other clinical trials performed by various parties including academic groups doing it for their own knowledge, and such studies may or may not have been used in support of a new drug approval application.
In the end, I tried to do an analysis over just the last several years focusing on drugs used in oncology. I came up with 85 approvals where I thought I might, on a reasonable basis, have at least some of the associated clinical trials used to support those approvals. But again, don’t make any important decisions based on this data. It’s just not that reliable.
Charts
There is a wealth of blended clinical and regulatory information to be mined. A data scientist can do all sorts of analysis to understand what clinical evidence is expected for a certain category of FDA drug approvals. Here’s just a sampling of the analysis that could be done, using the oncology drug data set I created as an example.
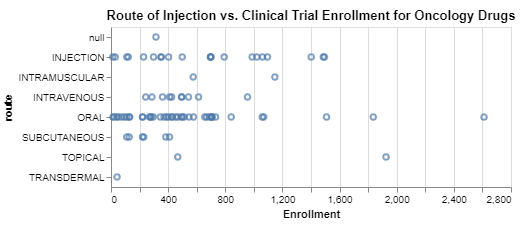
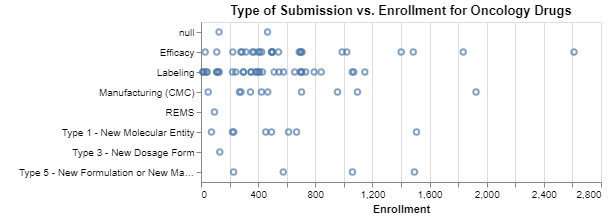
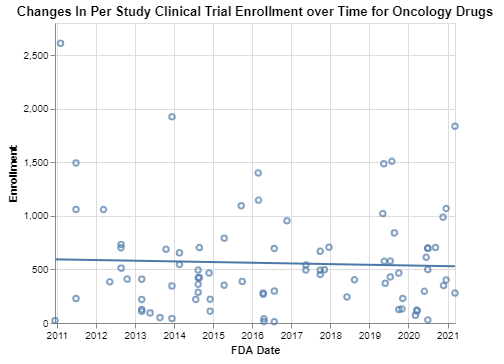
Interpretation
In the first chart, it looks like perhaps oncology clinical trials that focus on drugs administered subcutaneously can have smaller enrollments. In the second chart, not surprisingly, efficacy submissions seem to require more data in many cases, but maybe surprisingly little data in at least some cases. If these data are to be believed, the third chart suggests that the average enrollment of oncology clinical trials has come down very slightly. I did not expect that, and frankly I question the reliability of these data for all the reasons explained above.
Hopefully, though, you can see how being able to connect clinical trials to the FDA regulatory database for new drugs could provide all sorts of insights into how FDA approaches the drug approval process. Whether you are a manufacturer seeking to understand what is expected for your future drug applications, or whether you’re a citizen data scientist who simply wants to understand better how FDA is protecting the American public by requiring appropriate evidence, connecting these dots is indispensable to that sort of assessment.
If you want to see or do this kind of analysis in the future, you might consider letting FDA know how much you would appreciate them following through with Commissioner Gottlieb’s 2018 announcement.
* * * *
The Unpacking Averages® blog series digs into FDA’s data on the regulation of medical products, going deeper than the published averages. The opinions expressed in this publication are those of the author(s). Subscribe to this blog for email notifications.